Attaching package: 'MASS'
The following object is masked from 'package:dplyr':
select
Why multiple variables matter
We are going to investigate the relationship between a person’s salary and their level of neuroticism. Neuroticism is a trait that reflects a person’s level of emotional stability. It is often defined as a negative personality trait involving negative emotions, poor self-regulation (an inability to manage urges), trouble dealing with stress, a strong reaction to perceived threats, and the tendency to complain.
Rows: 1000 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): Education
dbl (2): Salary, Neuroticism
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
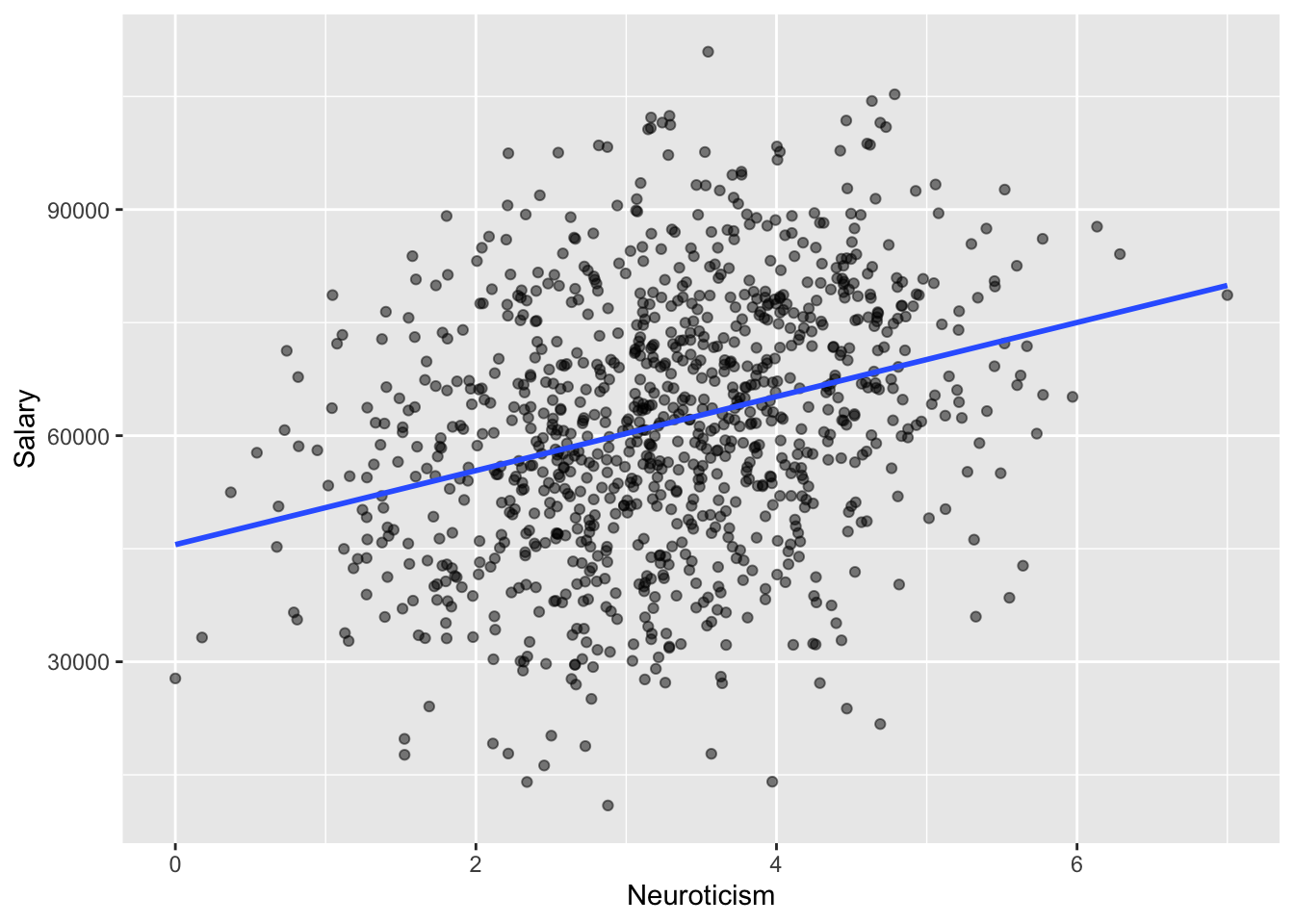
Assume we are going to investigate this using a linear model. Make an appropriate visualization to assess the relationship between salary and neuroticism. Comment on the relationship. Fit a line using method = "lm.
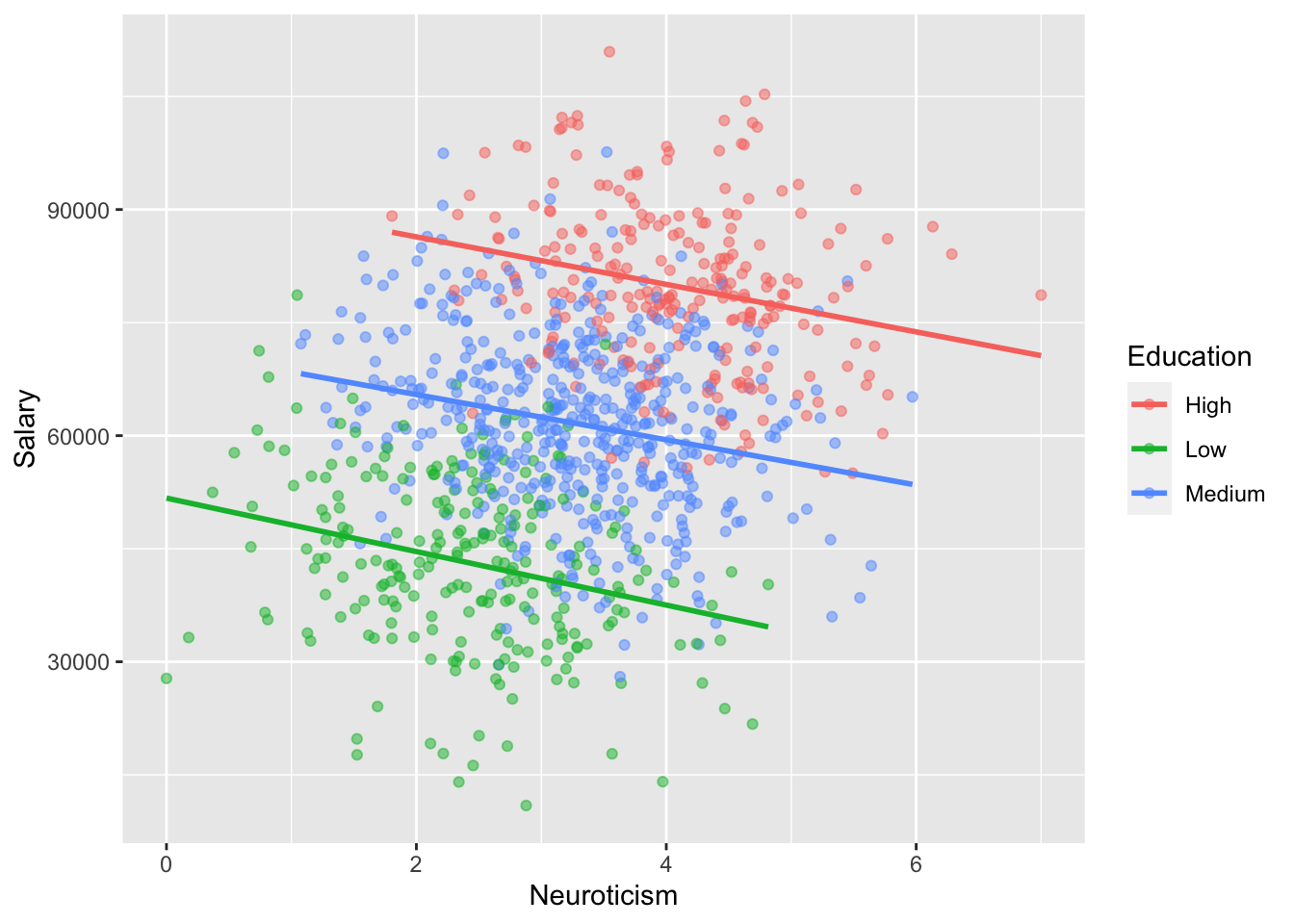
As you may have noticed, we also have levels of education as a categorical variable with levels Low, Medium, and High. A fellow researcher suggests to include this information in the model to “account for it” when looking at the relationship between salary and neuroticism. Make an updated visualization that includes level of education as the z variable, and comment on the relationship between salary and neuroticism below. Fit lines using method = "lm for each of the three levels of education.
data|>ggplot(aes(y =Salary, x =Neuroticism , color =Education))+geom_point(alpha =0.5)+geom_smooth(method ="lm" , se =F)
`geom_smooth()` using formula = 'y ~ x'
What is going on? What is this called?
The relationship flipped! This is Simpson’s paradox.
Model Selection: Penguins
Last class (and in warm up), we went over why \(R^2\) is not a good tool for model selection. Let’s go over some more appropriate model selections tools to pick the “best” model from a subset.
Model Selection Notes:
Before we show how to do this in R…..
Note! Please read!
It is a bad idea to simply let R alone choose your best fitting model for you. Good practices include:
– Talking with the subject expert about variables that must or should not be in your model
– Align variables to your research question. This includes:
— keeping the variables you are interested in…. and the variables you want to account for…
— We use this as evidence, along with other sources of evidence to justify our model selection
Adjusted R-squared
Fit three models that we have gone over in class thus far, and use adjusted r-squared to justify which model is most appropriate. Hint: In the same pipe used to fit the model, use glance |> pull(adj.r.squared) to get the appropriate information. You can also use glance(model.name)$adj.r.squared.
Model 1: body mass vs flipper length
slr<-linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm , data =penguins)glance(slr)$AIC
[1] 5062.855
linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm , data =penguins)|>glance()|>pull(adj.r.squared)
[1] 0.7582837
Model 2: body mass vs flipper length + island
mrl_add<-linear_reg()|>set_engine("lm")|>fit(body_mass_g~island+flipper_length_mm, data =penguins)glance(mrl_add)$AIC
The Akaike information criterion (AIC) is an estimator of relative quality of statistical models for a given set of data.
You can calculate this in R much like you do adjusted r-squared: use glance |> pull(AIC) or glance(model.name)$AIC. Try it above!
Backwards Selection
Backward elimination starts with the the model that includes all potential predictor variables. Variables are eliminated one-at-a-time from the model until we cannot improve the model any further.
Procedure:
– Start with a full model that has all predictors we consider and compute the AIC or adjusted-r-squared.
– Next fit every possible model with 1 less predictor.
– Compare AIC or adjusted-r-squared scores to select the best model with 1 less predictor if they show improvement over full model.
– Repeat steps 2 and 3 until you score the model with no predictors.
– Compare AIC or adjusted-r-squared among all tested models to select the best model.
Example
To better understand the idea of backwards selection, we are going to manually walk through one iteration of the procedure above. Our “full” model will be defined as an additive model with flipper length, and island on our response body mass. With this information, perform backwards selection and report which variable will not be in the final backward elimination model (if at all). Use AIC as your criteria.
Hint: In the same pipe used to fit the model, instead of using tidy(), use glance |> pull(AIC) to get the appropriate information.
linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm+bill_length_mm+island, data =penguins)|>glance()|>pull(AIC)
[1] 5035.615
## Choose the model above linear_reg()|>set_engine("lm")|>fit(body_mass_g~bill_length_mm+island, data =penguins)|>glance()|>pull(AIC)
[1] 5216.441
Forward Selection
Procedure:
– Start with a model that has no predictors i.e. just model the response with a constant term.
– Next fit every possible model with 1 additional predictor and score each model.
– Compare AIC scores to select the best model with 1 additional predictor vs first model.
– Repeat steps 2 and 3 until you can no longer improve the model.
– Perform 1 step of forward selection using the same variables mentioned above. What variable will be in the final forward selection model?
For this example, let’s use bill length and island as our only two predictors for body mass.
Hint: We can fit a model with no predictors using ~ 1 in place of any explanatory variable.
linear_reg()|>set_engine("lm")|>fit(body_mass_g~1 , data =penguins)|>glance()|>pull(AIC)
[1] 5547.496
### island, flipper length, bill length linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm, data =penguins)|>glance()|>pull(AIC)
[1] 5062.855
linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm+island, data =penguins)|>glance()|>pull(AIC)
[1] 5044.513
linear_reg()|>set_engine("lm")|>fit(body_mass_g~flipper_length_mm*island*bill_length_mm, data =penguins)|>glance()|>pull(AIC)
[1] 4997.089
Notes about model selection
– what a “meaningful” difference? You should set it
– backward elimination and forward selection sometimes arrive at different final models
So which do I choose?
Forward stepwise selection is used when the number of variables under consideration is very large
Starting with the full model (backward selection) has the advantage of considering the effects of all variables simultaneously.
Optional
Stepwise in R
People use stepwise selection when their goal is to pick the overall “best” model.
There are many functions that will allow you to perform stepwise selection in R. Today, we are going to introduce ourselves to stepAIC. Currently, performing stepwise selection is very difficult with tidymodels, so we are going to write our models in base R using the lm function. Let’s do this below.
In stepAIC, the arguments are:
object: your model name
scope: your “full model”
direction: “forward”, or “backward”.
lm_fwd<-lm(body_mass_g~island, data =penguins)stepAIC(lm_fwd, scope =~bill_length_mm+island+flipper_length_mm, direction ="forward")
Start: AIC=4407.88
body_mass_g ~ island
Df Sum of Sq RSS AIC
+ flipper_length_mm 1 83480840 49512346 4072.0
+ bill_length_mm 1 51139275 81853911 4243.9
<none> 132993186 4407.9
Step: AIC=4071.96
body_mass_g ~ island + flipper_length_mm
Df Sum of Sq RSS AIC
+ bill_length_mm 1 1552910 47959436 4063.1
<none> 49512346 4072.0
Step: AIC=4063.06
body_mass_g ~ island + flipper_length_mm + bill_length_mm