Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
if_else
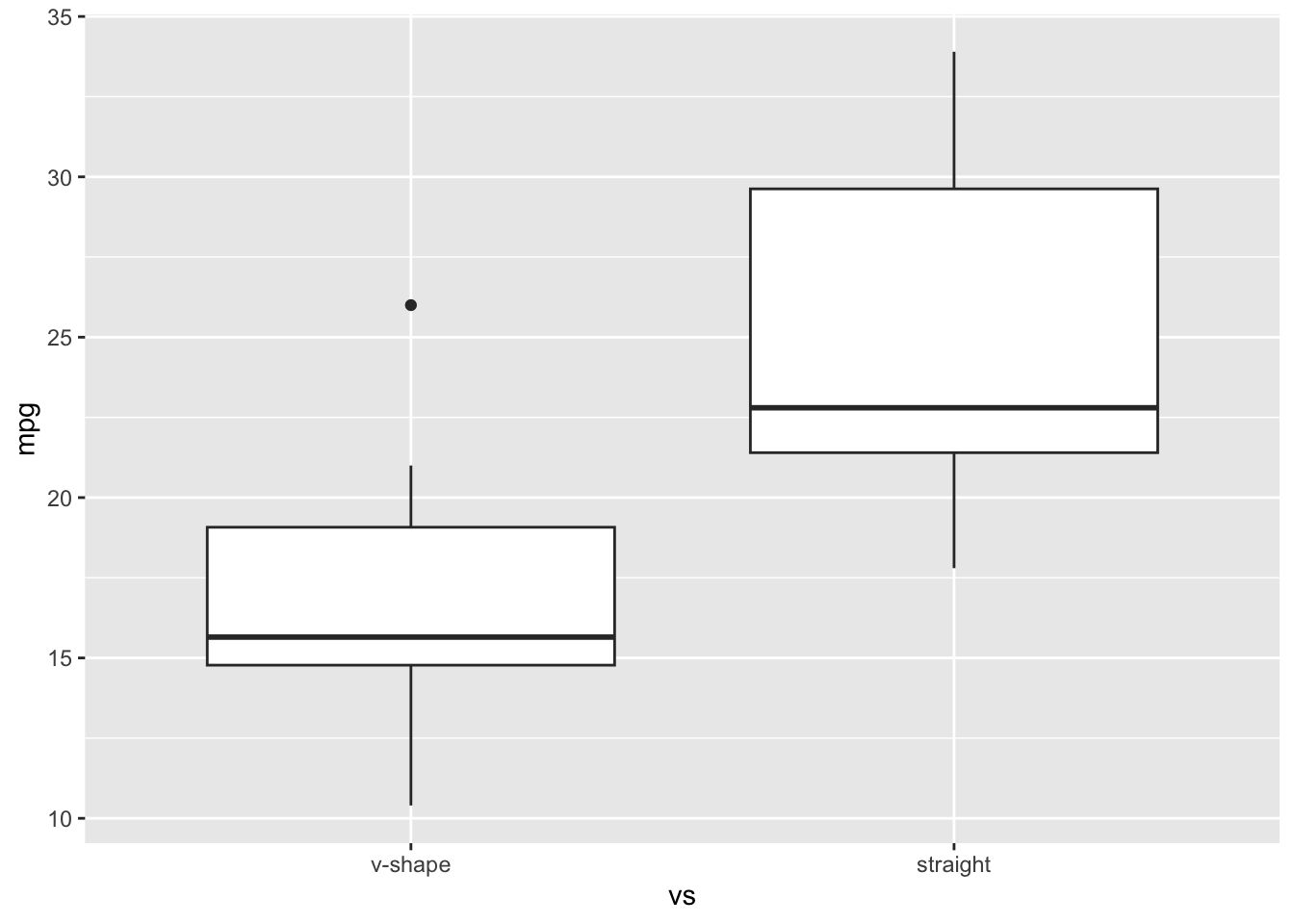
Instead of changing vs to a factor and changing the labels, let’s create a new variable called vs_cat
Friendly reminder that if you wanted to change the vs variable instead of making a new one, we can do that too!
scales
scales
scale_x_continuous
scale_y_continuous
scale_x_discrete
scale_y_discrete
In the following activity, we are going to define the four following functions and nest label and breaks within each to really take control of our plots.
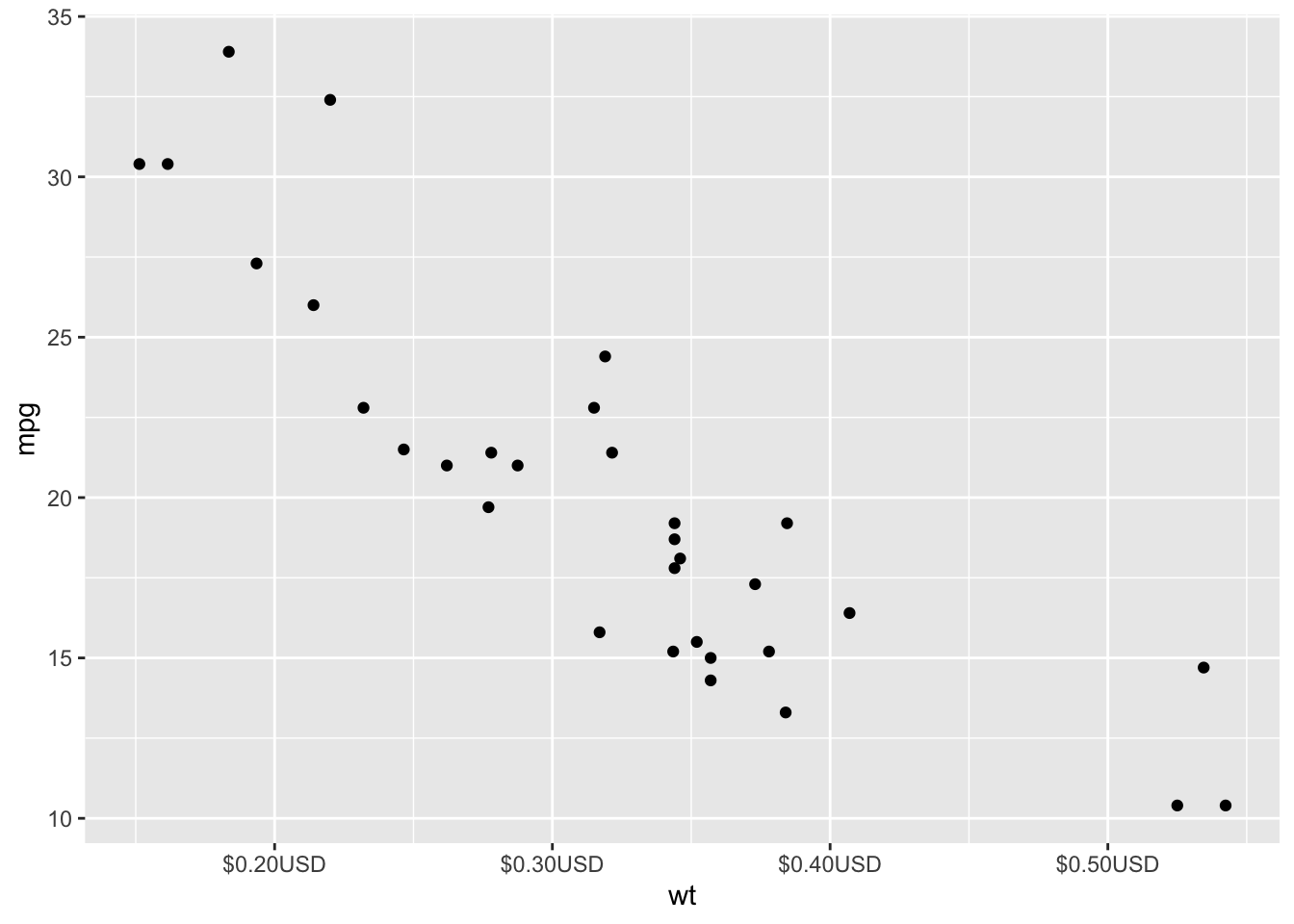
Dollar
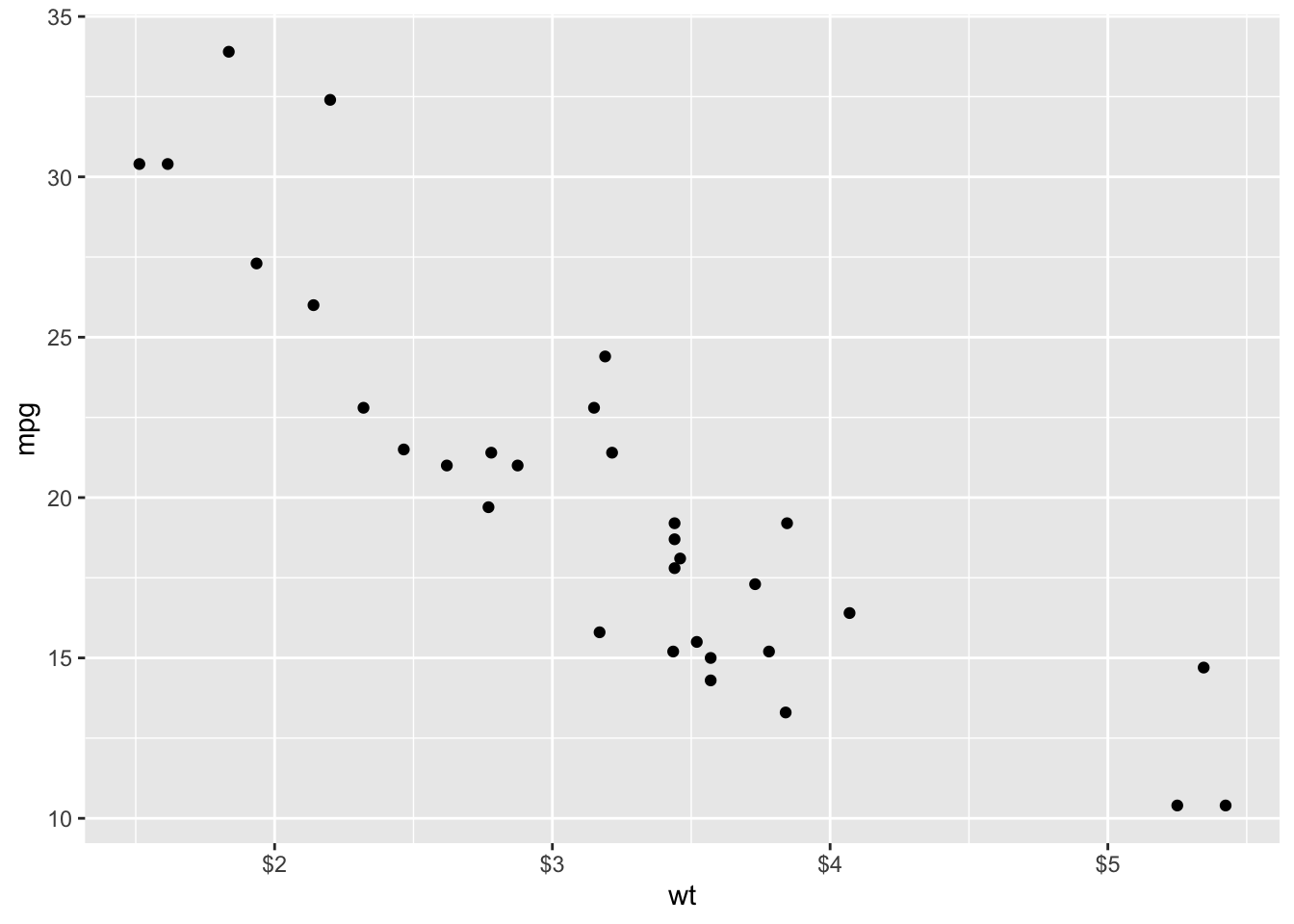
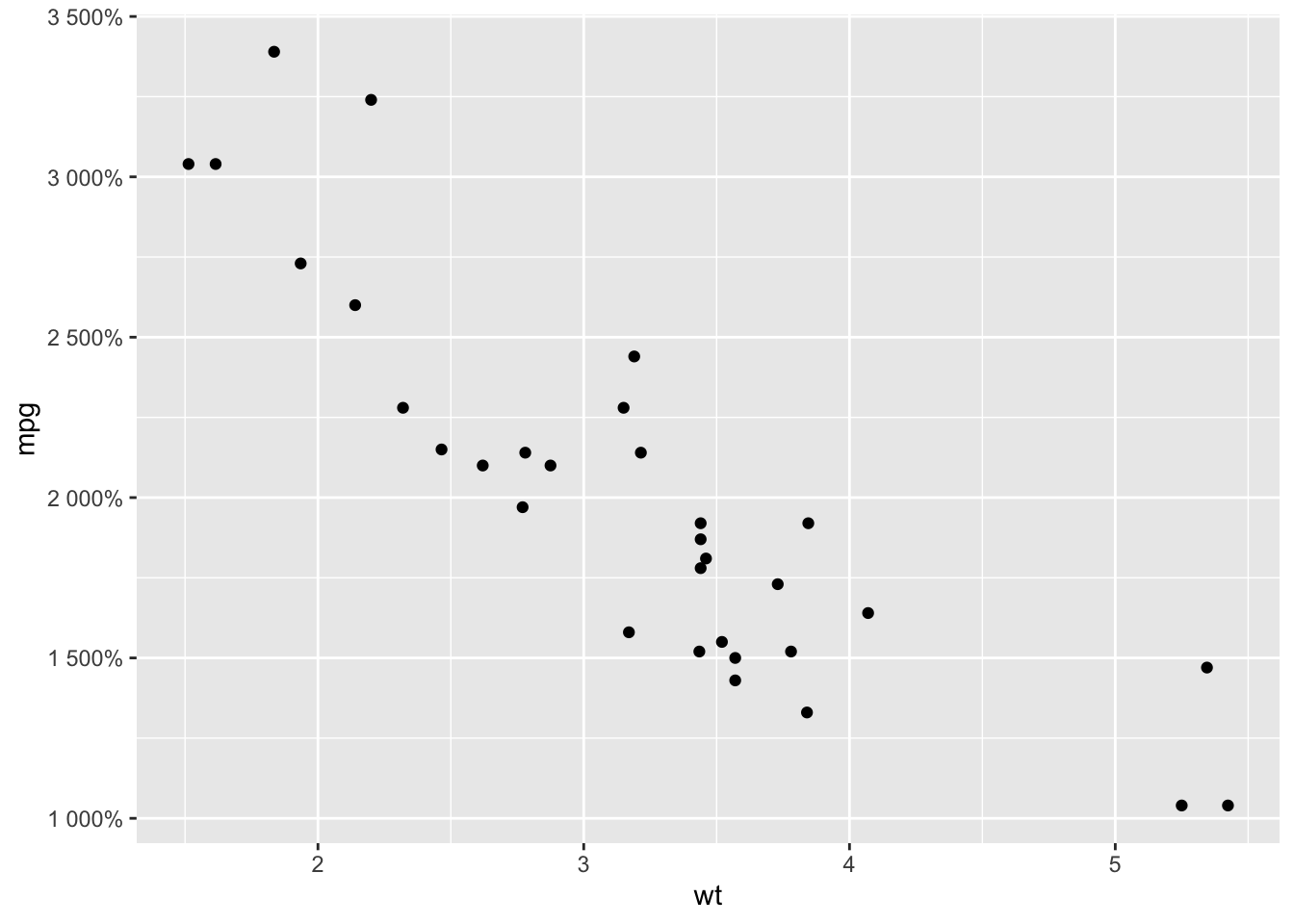
Plots look better with labels. We can also label the units using the above functions + labels! Comment the code below.
Often, we can use these scale functions to control the range of our axes. To do so, we set up a sequence with a start, finish, and tell R how to move between the points.
How does this change if we are working with a categorical variable?
We don’t have a quantitative variable to sequence over in the following situation. When working with a quantitative variable, we may want to change the label of the groups. Their are multiple ways to do this. 1) We could change the physical data set using mutate, or we could relabel our plot using the following:
This is just a quick example. You can do so much more. For an outside source, please visit here
Working with multiple data frames
Often instead of being provided the data you need for your analysis in a single data frame, you will need to bring information from multiple datasets together into a data frame yourself. These datasets will be linked to each other via a column (usually an identifier, something that links the two datasets together) that you can use to join them together.
There are many possible types of joins. All have the format something_join(x, y).
Study Tip change the x and y data sets to different situations you are curious about and practice joining them together to see what happens!
x<-tibble( value =c(1, 2, 3), xcol =c("x1", "x2", "x3"))y<-tibble( value =c(1, 2, 4), ycol =c("y1", "y2", "y4"))x
# A tibble: 3 × 2
value xcol
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3
y
# A tibble: 3 × 2
value ycol
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y4
We will demonstrate each of the joins on these small, toy datasets.
Note: These functions below know to join x and y by value because each dataset has value as a column. See for yourself!
Takeaway: R will default to join 2 data sets together by ALL common variable names. If we don’t want this, we can override that by setting the key using by = . When we have more than one variable as the key, we need to look for matches across the first variable AND for matches across the second variable before joining data sets together.